SGLang Config: Advanced Engine Deployment#
--sglang-config is a YAML-based configuration system for fine-grained control over SGLang engine deployment in slime. It enables multi-model serving, Prefill-Decode (PD) disaggregation, heterogeneous server groups, and can even serve as a standalone SGLang launcher for complex inference topologies.
Architecture Overview#
In the default setup (without --sglang-config), slime deploys a single model behind a single router with uniform server groups:
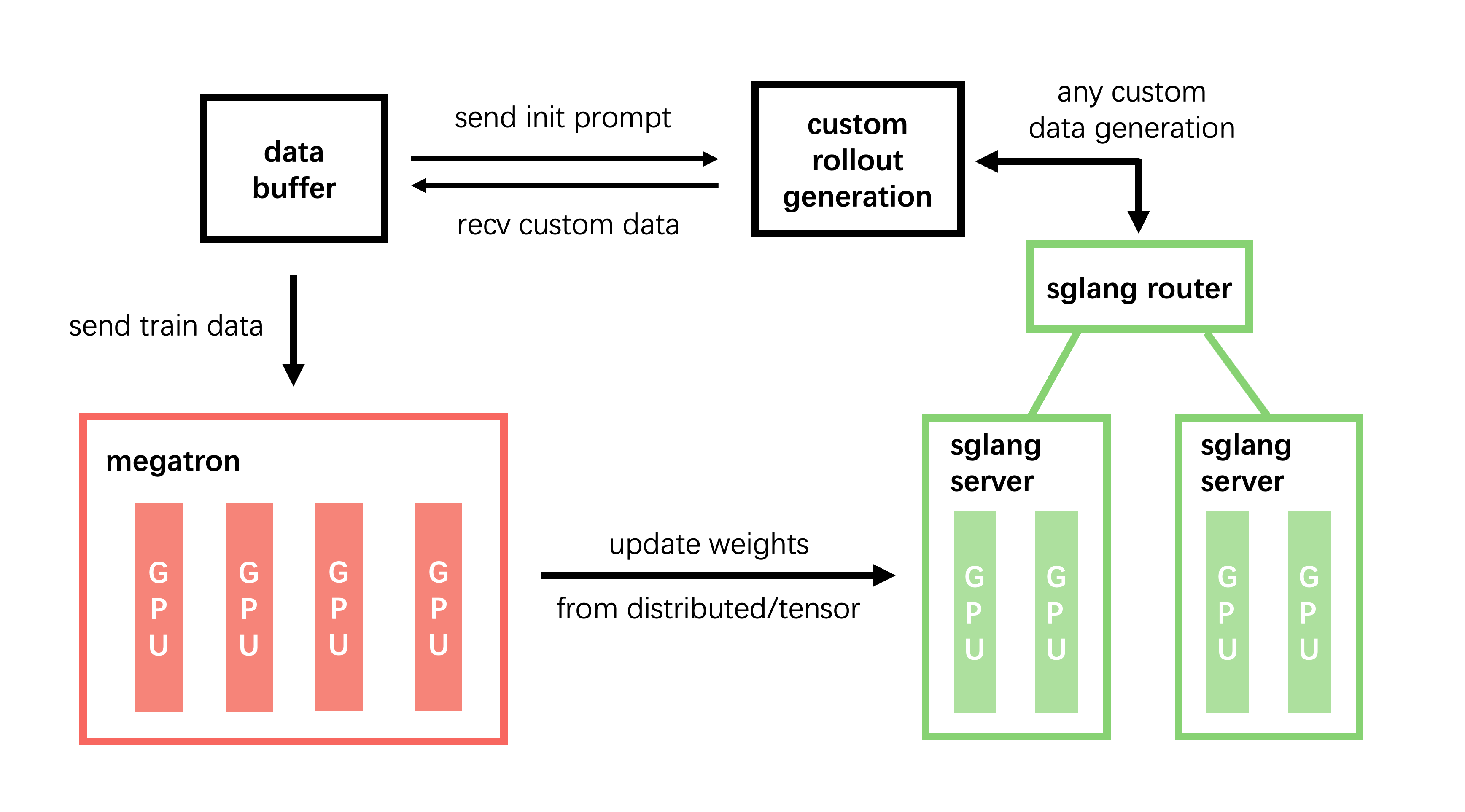
With --sglang-config, the SGLang deployment expands into a multi-model, multi-router topology:
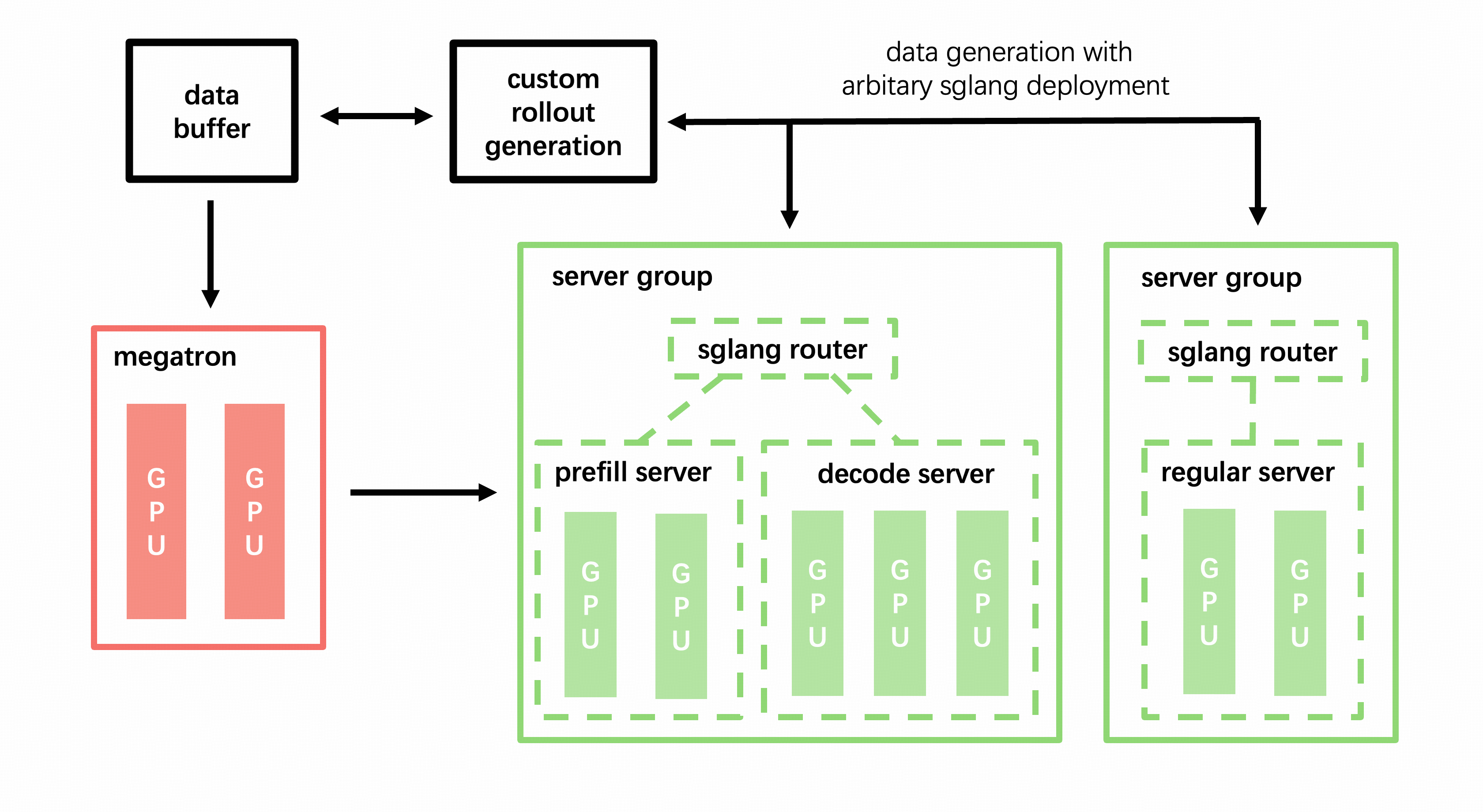
Key design principles:
Each model gets its own router. Models are isolated at the routing layer, allowing independent load balancing and fault tolerance.
Server groups within a model can be heterogeneous. Different groups can have different TP sizes, worker types (prefill/decode/regular), and SGLang server argument overrides.
Weight sync is per-model. Only models with
update_weights: truereceive weight updates from training. Frozen models (reference, reward, etc.) are served as-is.
Config Format#
The config file is a YAML document with a top-level sglang key containing a list of model definitions:
sglang:
- name: <model_name> # Required. Unique identifier for this model.
model_path: <path> # Optional. HF checkpoint path. Defaults to --hf-checkpoint.
update_weights: <bool> # Optional. Whether to sync weights from training. Auto-inferred.
num_gpus_per_engine: <int> # Optional. Default TP size for all groups in this model.
server_groups: # Required. List of server group configurations.
- worker_type: <type> # Required. One of: regular, prefill, decode, placeholder.
num_gpus: <int> # Required. Total GPUs allocated to this group.
num_gpus_per_engine: <int> # Optional. TP size override for this group.
overrides: <dict> # Optional. SGLang ServerArgs field overrides.
Field Reference#
Model-Level Fields#
Field |
Type |
Default |
Description |
|---|---|---|---|
|
|
Required |
Unique name for this model (e.g., |
|
|
|
HuggingFace checkpoint path. All server groups within a model must use the same model path. |
|
|
Auto |
Whether this model receives weight updates from training. When not set, automatically inferred: |
|
|
|
Default TP size for server groups in this model. Individual groups can override. |
|
|
Required |
List of |
Server Group Fields#
Field |
Type |
Default |
Description |
|---|---|---|---|
|
|
Required |
Engine type: |
|
|
Required |
Total number of GPUs for this group. Must be > 0. |
|
|
Model’s |
TP size override. Number of GPUs per engine instance. |
|
|
|
SGLang |
Worker Types#
Type |
Description |
Use Case |
|---|---|---|
|
Standard SGLang engine |
Default mode, handles both prefill and decode |
|
PD disaggregation prefill worker |
Dedicated to prompt processing; paired with |
|
PD disaggregation decode worker |
Dedicated to token generation; paired with |
|
Reserves GPU slots, no engine created |
Reserve GPUs for training co-location or future use |
Usage Patterns#
1. Basic Single-Model Deployment#
The simplest config replicates the default behavior:
# sglang_basic.yaml
sglang:
- name: default
server_groups:
- worker_type: regular
num_gpus: 8
python train.py \
--sglang-config sglang_basic.yaml \
--rollout-num-gpus 8 \
--rollout-num-gpus-per-engine 2 \
...
This creates 4 engines (8 GPUs ÷ 2 GPUs/engine) behind a single router.
2. PD Disaggregation#
Separate prefill and decode phases onto dedicated server groups for better throughput in multi-turn and agentic workloads:
# sglang_pd.yaml
sglang:
- name: actor
server_groups:
- worker_type: prefill
num_gpus: 4
num_gpus_per_engine: 2 # 2 prefill engines, TP=2
- worker_type: decode
num_gpus: 12
num_gpus_per_engine: 4 # 3 decode engines, TP=4
python train.py \
--sglang-config sglang_pd.yaml \
--rollout-num-gpus 16 \
...
Why PD disaggregation? In multi-turn scenarios, prefill and decode have different compute characteristics. Prefill is compute-bound (processes the entire prompt), while decode is memory-bandwidth-bound (generates tokens one-by-one). Disaggregating them allows:
Using smaller TP for prefill (higher throughput per GPU)
Using larger TP for decode (lower latency)
Independent scaling of prefill vs. decode capacity
Note: PD disaggregation uses SGLang Model Gateway (sgl-router) with
pd_disaggregation=True.
3. Multi-Model Serving#
Deploy multiple models simultaneously, each behind its own router:
# sglang_multi_model.yaml
sglang:
- name: actor
update_weights: true # receives weight updates from training
server_groups:
- worker_type: regular
num_gpus: 8
num_gpus_per_engine: 4
- name: ref
model_path: /path/to/ref_model # different model checkpoint
update_weights: false # frozen, no weight updates
server_groups:
- worker_type: regular
num_gpus: 4
num_gpus_per_engine: 2
- name: reward
model_path: /path/to/reward_model
update_weights: false
server_groups:
- worker_type: regular
num_gpus: 4
num_gpus_per_engine: 2
python train.py \
--sglang-config sglang_multi_model.yaml \
--rollout-num-gpus 16 \
--hf-checkpoint /path/to/actor_model \
--rollout-function-path my_rollout.generate_rollout \
...
Accessing models in custom rollout functions:
from slime.rollout.sglang_rollout import get_model_url
from slime.utils.http_utils import post
async def my_generate(args, sample, sampling_params):
# Route to the actor model (default)
actor_url = get_model_url(args, "actor", "/generate")
output = await post(actor_url, {"text": sample.prompt, "sampling_params": sampling_params})
# Route to the reference model
ref_url = get_model_url(args, "ref", "/generate")
ref_output = await post(ref_url, {"text": sample.prompt, "sampling_params": sampling_params})
# Route to the reward model (e.g., OpenAI-compatible API)
reward_url = get_model_url(args, "reward", "/v1/chat/completions")
reward_output = await post(reward_url, {...})
...
The get_model_url() helper reads from args.sglang_model_routers, a dict mapping model names to (ip, port) tuples that is automatically populated after engine startup.
4. Multi-Model with PD Disaggregation#
Combine multi-model and PD disaggregation for maximum flexibility:
# sglang_full.yaml
sglang:
- name: actor
update_weights: true
server_groups:
- worker_type: prefill
num_gpus: 4
num_gpus_per_engine: 2
- worker_type: decode
num_gpus: 8
num_gpus_per_engine: 4
- name: ref
model_path: /path/to/ref_model
update_weights: false
server_groups:
- worker_type: regular
num_gpus: 4
num_gpus_per_engine: 2
5. Placeholder Groups for GPU Reservation#
Use placeholder groups to reserve GPU slots without creating engines. This is useful for co-located training where some GPUs need to be reserved for training:
sglang:
- name: actor
server_groups:
- worker_type: regular
num_gpus: 6
num_gpus_per_engine: 2
- worker_type: placeholder
num_gpus: 2 # reserve 2 GPUs (no engines created)
6. Per-Group ServerArgs Overrides#
Use overrides to apply SGLang ServerArgs fields to specific server groups without affecting others:
sglang:
- name: actor
server_groups:
- worker_type: regular
num_gpus: 8
num_gpus_per_engine: 4
overrides:
mem_fraction_static: 0.85
context_length: 32768
chunked_prefill_size: 4096
enable_torch_compile: true
Overrides take highest priority, overriding both the base --sglang-* CLI args and model-level defaults. This is especially useful for:
Different memory configurations per group
Different context lengths for prefill vs. decode
Enabling experimental features on specific groups
7. Standalone SGLang Launcher#
While --sglang-config is designed for slime’s training pipeline, it also works as a powerful launcher for pure inference scenarios using external engine addresses or by configuring slime to focus solely on serving.
Using external engines with a pre-launched topology:
For complex production deployments, you may want to pre-launch SGLang engines independently and connect them to slime:
# Step 1: Launch SGLang engines externally
python -m sglang.launch_server --model-path /path/to/model --port 10090 ...
python -m sglang.launch_server --model-path /path/to/model --port 10091 ...
# Step 2: Connect slime to external engines
python train.py \
--rollout-external-engine-addrs host1:10090 host2:10091 \
...
slime queries each external engine’s /server_info endpoint to infer
rollout_num_gpus, per-engine GPU counts, SGLang parallel sizes, and
prefill/decode worker types. If no --sglang-router-ip/--sglang-router-port
is provided, slime launches its own router and registers the external engines
to it.
Note:
--sglang-configand--rollout-external-engine-addrsare mutually exclusive. Use--sglang-configwhen you want slime to manage the full engine lifecycle; use--rollout-external-engine-addrswhen engines are pre-deployed.
For external-engine selection, update from disk, and delta disk transport, see External Rollout Engines Roadmap.
Router Configuration#
Each model in the config gets its own independent router (SGLang Model Gateway by default).
Router Policies#
You can configure the routing policy:
--router-policy round_robin # Simple round-robin
--router-policy consistent_hashing # Session affinity for multi-turn
--router-policy cache_aware # Cache-aware routing (default)
Session-Affinity Routing for Multi-Turn Agents#
For multi-turn dialogues and agentic workloads, session affinity ensures that all requests belonging to the same conversation are routed to the same backend worker. This significantly improves prefix cache hit rates because the worker already has the conversation history cached.
slime automatically assigns each sample a unique session_id (stored in sample.session_id). When the router policy is consistent_hashing, this ID is passed as the X-SMG-Routing-Key header, and SGLang Model Gateway uses it to deterministically route all turns of the same session to the same worker.
--router-policy consistent_hashing
How it works:
Each sample is assigned a unique
session_idvia UUIDOn each request, slime passes
X-SMG-Routing-Key: <session_id>in the HTTP headerSGLang Model Gateway’s consistent hashing policy maps this key to a specific worker
Subsequent turns reuse the same
session_id, ensuring they hit the same worker
Resolution Rules#
When the config is loaded, slime applies the following resolution cascade:
GPU per engine fallback: Group
num_gpus_per_engine→ Modelnum_gpus_per_engine→args.rollout_num_gpus_per_engineModel path fallback: Group
overrides.model_path→ Modelmodel_path→args.hf_checkpointWeight update inference: If
update_weightsis not set:trueif the effective model path matches--hf-checkpointfalseotherwise (with a warning)
Total GPU validation: The sum of all
num_gpusacross all groups across all models must equal--rollout-num-gpus.
Mutual Exclusion#
--sglang-config is mutually exclusive with:
Flag |
Conflict Reason |
|---|---|
|
PD disaggregation is configured via |
|
External engines have their own topology; config manages the lifecycle internally |
Complete Example: Multi-Model Agentic Training#
Below is a complete example showing a multi-model setup for agentic RL training with PD disaggregation on 32 GPUs:
Config file (sglang_agent.yaml):
sglang:
- name: actor
update_weights: true
server_groups:
- worker_type: prefill
num_gpus: 4
num_gpus_per_engine: 2
overrides:
chunked_prefill_size: 8192
- worker_type: decode
num_gpus: 12
num_gpus_per_engine: 4
overrides:
mem_fraction_static: 0.88
- name: ref
model_path: /data/models/Qwen3-32B
update_weights: false
server_groups:
- worker_type: regular
num_gpus: 8
num_gpus_per_engine: 4
- name: reward
model_path: /data/models/reward-model
update_weights: false
server_groups:
- worker_type: regular
num_gpus: 8
num_gpus_per_engine: 4
Launch command:
python train.py \
--sglang-config sglang_agent.yaml \
--hf-checkpoint /data/models/Qwen3-8B \
--rollout-num-gpus 32 \
--rollout-function-path my_agent.rollout.generate_rollout \
--custom-rm-path my_agent.reward.reward_func \
--advantage-estimator grpo \
--n-samples-per-prompt 8 \
...
Custom rollout function (my_agent/rollout.py):
from slime.rollout.sglang_rollout import get_model_url
from slime.utils.http_utils import post
async def generate_with_models(args, sample, sampling_params):
"""Generate using actor, score with reward model, compare with reference."""
# Generate from actor
actor_url = get_model_url(args, "actor", "/generate")
actor_output = await post(actor_url, {
"text": sample.prompt,
"sampling_params": sampling_params,
"return_logprob": True,
})
# Get reference logprobs for KL penalty
ref_url = get_model_url(args, "ref", "/generate")
ref_output = await post(ref_url, {
"text": sample.prompt + actor_output["text"],
"sampling_params": {"max_new_tokens": 0, "temperature": 0},
"return_logprob": True,
})
# Score with reward model
reward_url = get_model_url(args, "reward", "/v1/chat/completions")
reward_output = await post(reward_url, {
"model": "reward",
"messages": [{"role": "user", "content": sample.prompt + actor_output["text"]}],
})
# ... process outputs and return Sample
FAQ#
Q: Can I mix PD and regular groups in the same model?#
No. PD disaggregation requires that a model’s server groups are either all prefill/decode pairs or all regular. Mixing regular with prefill/decode in the same model is not supported.
Q: What happens if num_gpus is not divisible by num_gpus_per_engine?#
For multi-node engines (where num_gpus_per_engine > num_gpus_per_node), the division is based on the local GPU count per node. For example, with 8 GPUs/node and num_gpus_per_engine: 16, each engine spans 2 nodes.
Q: Can different server groups within a model use different model paths?#
No. All server groups within a model must share the same model_path. This is validated during resolve(). If you need different models, define them as separate model entries.
Q: How do I access the router address for a specific model at runtime?#
Use get_model_url(args, "model_name", "/endpoint") from slime.rollout.sglang_rollout. It reads from args.sglang_model_routers, which is a dict { model_name: (ip, port) } populated automatically.
Q: Can I use --sglang-config without training (inference only)?#
While --sglang-config is designed for slime’s training loop, you can effectively use it for inference-only scenarios by configuring a rollout-only run. For fully standalone SGLang serving, consider using SGLang’s native launch_server directly or --rollout-external-engine-addrs for connecting to pre-deployed engines.
Q: What is the relationship between --sglang-config and --prefill-num-servers?#
--prefill-num-servers is the legacy way to enable PD disaggregation (it creates a single model with prefill + decode groups). --sglang-config is the newer, more flexible approach. They are mutually exclusive. We recommend migrating to --sglang-config for all new deployments.