v0.1.0: Redefining High-Performance RL Training Frameworks#
The origin version of this article is in Chinese and was first released in zhihu.
With the help of the community, we’ve finally released the first version of slime, v0.1.0, just two months after it was open-sourced.
In a nutshell, this version can be summarized as follows:
slime v0.1.0 provides all the essential performance optimizations needed for large-scale MoE RL training.
Specifically, this version brings the following improvements:
Performance:
Provides efficient inference for MoE models, especially with fp8 rollout + deepep + mtp.
Designed a generic training framework memory offload solution to save more KV Cache space, thus increasing inference concurrency.
Faster parameter updates.
Achieves more training with fewer GPUs through CPU Adam.
Supports all of Megatron’s parallel strategies as well as deepep.
Features:
Added support for GSPO for MoE model training.
Added support for TIS for fp8 rollout.
Correctness:
Implemented Dense and MoE model CI to strictly check metrics like kl.
We hope to use slime v0.1.0 to demonstrate our understanding of high-performance RL training frameworks and have it become a baseline for future performance comparisons.
Next, I’ll elaborate on the design philosophy behind these features.
Performance Optimization: Pushing the Limits of RL Training Speed#
In traditional deep learning training, there’s a universal solution for speedup: add more GPUs. By reducing the amount of data processed per GPU, you can significantly lower end-to-end training latency.
However, this method doesn’t work for RL training because inference latency cannot be reduced by adding more GPUs. Even with more GPUs, we still have to wait for the longest sample to finish decoding. While increasing throughput can improve the amount of training data per rollout, the off-policy issues caused by an excessively large inference batch size still have some limitations.
I believe this is the biggest challenge for infrastructure under the current RL paradigm, which is:
We want to scale inference compute, but we cannot scale inference latency.
The decoding speed of a single data point determines the upper limit of RL training speed. For larger MoE models, there are currently three common optimization methods to push this limit, and we’ve tried all of them:
Reduce memory access through quantization: Considering that long calibration is not feasible in RL training, slime opts for fp8 quantization.
Use deepep low-latency mode to reduce all2all latency across machines: To work with deepep, slime recommends using blockwise quantization with fp8 to enable related SGLang configurations.
Enable Speculative Sampling: slime allows loading any draft model for the inference part (currently, it doesn’t support updating the draft model during training).
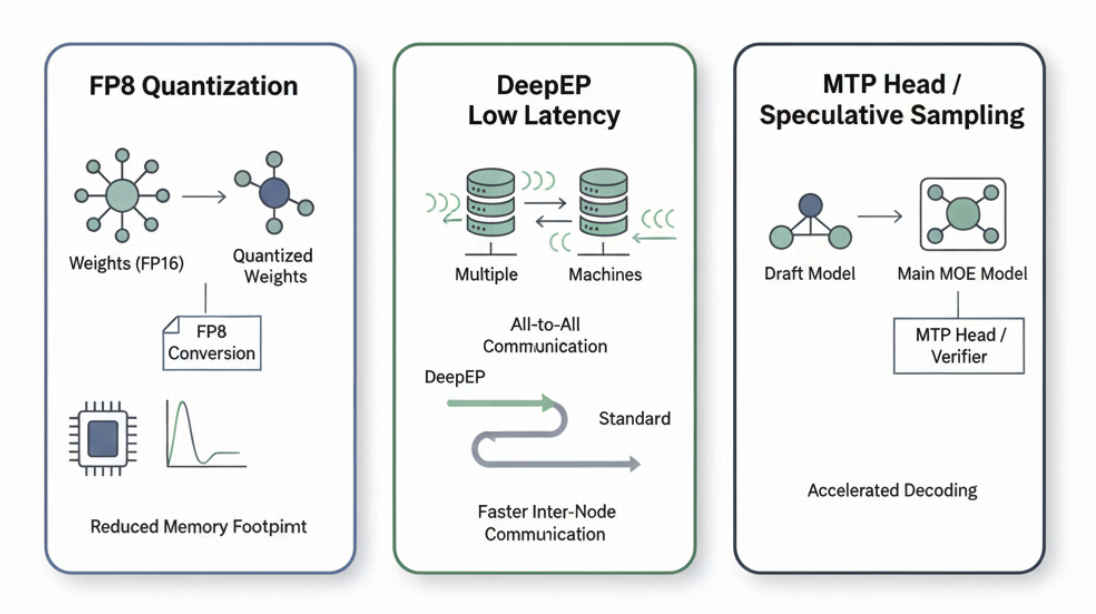
By using the three optimizations mentioned above, we can increase a model like GLM4.5 355B-A32B from less than 10 tokens/s for a single data point to 60-70 tokens/s, which significantly raises the upper limit of RL training speed.
In addition to monitoring inference throughput, slime also monitors perf/longest_sample_tokens_per_sec to better understand the potential for performance optimization in the inference part.
Doing More Experiments with Fewer GPUs: Fully Offloading Megatron#
After optimizing the upper limit, we noticed another characteristic of RL training: as long as the KV Cache doesn’t overflow, increasing the inference batch size doesn’t significantly affect training latency.
KV Cache overflow occurs during inference when the response lengths of the data are all very long, leading to insufficient KV Cache space. This requires kicking out some half-generated data from the queue and then re-running prefill and subsequent inference steps after other data has been processed and freed up space. If a data point with a response length of 64k has to wait for 32k tokens to be decoded by other data during its inference, its total time is equivalent to decoding 96k tokens. This greatly impacts the RL training speed.
Therefore, a more suitable training configuration is to calculate the minimum number of GPUs needed to prevent KV Cache overflow based on the inference batch size, the average response length, and the available KV Cache space on a single server. A group of these GPUs is then used for training. For example, if we have 512 GPUs and the calculation shows that 256 GPUs provide enough KV Cache, we should run two experiments in parallel instead of launching one experiment with all 512 GPUs.
Based on this consideration, we noticed two points for optimization:
The optimal number of GPUs may not be sufficient to load the training part. Inference only needs to load the fp8 parameters, while training generally requires more than 18 times the parameter size of GPU memory (bf16 param, fp32 grad, fp32 master param, fp32 m and v). To solve this, slime uses Megatron’s built-in CPU Adam to save GPU memory for the training part. This strategy allowed us to provide solutions for training GLM 4.5 355B-A32B with 8 nodes and DeepSeek R1 with 16 nodes.
Increase the KV Cache space available per SGLang Server, which means increasing
mem_fraction. For the more common integrated training and inference tasks, the main limitation for a largermem_fractionis the residual GPU memory after offloading the training part to the CPU. Therefore, we need to find a generic way to offload the GPU memory used by the Megatron part.
How to Offload GPU Tensors Generically#
One crude approach is to find all the GPU Tensors allocated by Megatron and call .to("cpu") on all of them. This method has three difficulties:
It’s hard to capture all GPU Tensors allocated by Megatron.
Because Megatron’s distributed optimizer reorganizes all parameters into some contiguous GPU buffers and then divides them with various slices, it’s difficult to properly handle all references to correctly free the GPU Tensors.
It requires checking the source code again with every new Megatron version, which is hard to maintain.
Is there a more generic solution?
We noticed that SGLang’s torch_memory_saver and VLLM’s cumem_allocator provide a more general offload solution. Their principle is that CUDA 10.2 provides a series of Virtual Memory Management APIs, similar to an operating system’s virtual and physical addresses (VA and PA). When allocating GPU memory, they return a handle to a memory mapping instead of the actual physical address. Therefore, when offloading, we only need to “secretly” release the memory corresponding to this mapping and reallocate it when this memory is needed. The upper-level application doesn’t need to be aware of this.
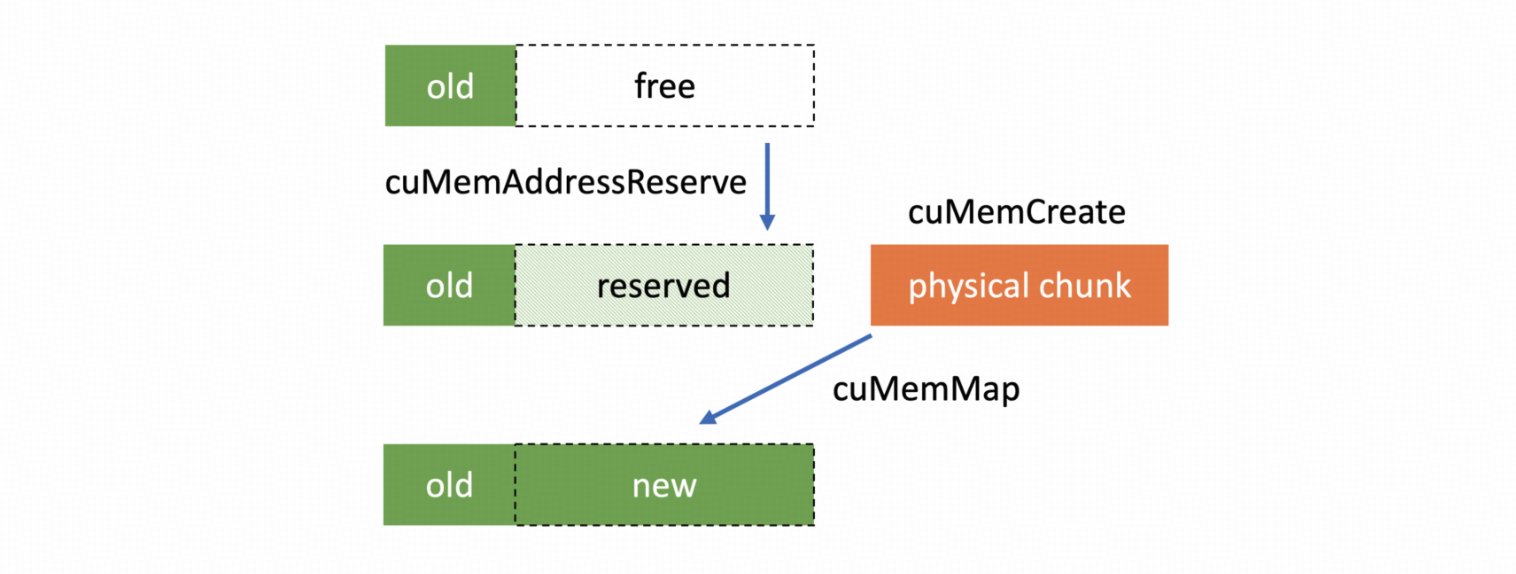
A natural idea is to use this method to take over the entire training process in RL. However, this prevents the reuse of PyTorch’s CUDACachingAllocator, and without the cache, memory fragmentation becomes more pronounced, easily leading to OOM during training.
To continue reusing the native, cached allocator, we cannot use CUDAPluggableAllocator. Noticing again that slime’s architecture has training and inference in different processes, we only need to directly replace cudaMalloc and cudaFree used by CUDACachingAllocator in the training process with VMM APIs via LD_PRELOAD. This allows us to completely and generically offload all GPU Tensors allocated by PyTorch.
At the same time, we must also note one detail: VMM APIs and cudaIPC APIs (such as cudaIpcGetMemHandle) are incompatible. Therefore, for integrated training and inference tasks and DeepEP, we need to disable the LD_PRELOAD replacement and switch back to cudaMalloc.
With help from the SGLang community, we updated torch_memory_saver for slime’s needs, implementing this offload solution.
How to Offload NCCL#
After thoroughly offloading the GPU Tensors in Megatron, we found that a large amount of GPU memory still remained, which was caused by NCCL. In PyTorch, each NCCL group involved in communication allocates a substantial buffer. This issue is particularly noticeable for larger MoE models due to the various parallel strategies, potentially taking up more than 10GB.
The LD_PRELOAD solution mentioned above doesn’t handle the NCCL issue well, and we don’t want to modify the NCCL source code to avoid having to maintain a separate NCCL fork in addition to slime. So, slime’s approach is to use destroy_process_group to destroy the NCCL group when offloading Megatron and then recreate it before loading Megatron. To do this, we mimicked the VMM API and monkey patched dist.new_group to add a layer of ReloadableProcessGroup.
In this way, we achieved a generic NCCL offload. However, because we need to rebuild the NCCL group, this operation has a slight impact on the speed of the first communication in each training iteration. But we believe this approach offers a significant advantage in terms of maintainability and the GPU memory it saves.
Combining these two optimizations, we reduced Megatron’s residual GPU memory from around 15-18GB to 3-5GB, which allows us to increase the mem_fraction for MoE models to 0.7-0.8. This significantly boosts the available KV Cache, increases the concurrency each server can support, and allows us to launch more training tasks with fewer GPUs.
Parameter Update Optimization#
Parameter update is another special step in RL training. For this, slime v0.1.0 provides the best optimization solution for scenarios where training and inference are in different processes. This work was heavily optimized by Biao He. I recommend reading his blog post:
Currently, slime can complete weight synchronization for a GLM4.5 355B-A32B model with bf16 weights in 48s and complete fp8 blockwise quantization + parameter update in 100s (the fp8 branch is still being optimized).
Training Optimization#
For the pure training part of slime, we believe Megatron already provides ample optimizations, so our main focus was to ensure compatibility with all of Megatron’s parallel strategies.
During this adaptation, we found an interesting bugfix: we discovered that when SGLang enabled mtp, the Megatron part couldn’t start DeepEP. It turned out that when mtp is enabled, SGLang disables the overlap schedule, which causes a certain metadata communication to use nccl instead of gloo after being offloaded to the CPU, and this conflicts with DeepEP.
Performance Optimization Check List#
Since the release of slime, I’ve often been asked about its performance comparison with other frameworks.
My understanding of benchmarks is that they should not be used as a weapon for frameworks to attack each other, but rather as a tool for identifying gaps. To that end, we will gradually release performance benchmarks that slime focuses on to improve ourselves.
I also believe that before running benchmarks, you can analyze a framework’s focus on performance from a qualitative perspective. Here’s a basic feature check list for optimizations:
Does it support MoE training? (Currently, large-scale experiments are focused on MoE)
Can the internal sglang
mem_fractionor vllmgpu_utilizationbe adjusted to over 0.7? (Ensures KV Cache space)Does it support fp8 or lower precision inference? (Reduces inference memory access, boosts speed)
Does it support enabling deepep for both training and inference? (Optimizes MoE all2all communication)
Does it support speculative sampling? (Improves inference latency and throughput)
Does it have an efficient training backend, such as Megatron or torchtitan, and support all necessary parallelization strategies? (Reuses mature training optimizations)
slime v0.1.0 has made preliminary attempts at all the above optimizations, and there’s still a lot of room for improvement. We hope this version can serve as a baseline for future slime versions or for performance comparisons between different frameworks. We also welcome all friends who share our pursuit of performance to try out slime and join the slime community!
New Algorithm Support#
To better train MoE models and perform fp8 rollouts, we implemented GSPO and TIS. Additionally, community experts have helped implement algorithms like reinforce++ and reinforce++ baseline.
Correctness Verification#
slime v0.1.0 adds end-to-end CI: we run single-machine GLM4 9B and Qwen3 30B-A3B training for each PR, ensuring correctness through strict checks. For example, we explicitly require:
The recomputed log prob of the first rollout must be exactly equal to the log prob of the reference model.
The ppo_kl of the first training step within each rollout must be exactly 0.
Such precise verification is rarely achieved in training frameworks, and it’s something we are very proud of.
This is a brief introduction to slime v0.1.0. I hope it sparks your curiosity about slime and that it can be helpful in your work.
Everyone is welcome to join the slime community. Let’s work together to build an open RL Infra and contribute to RL scaling!